# Paxos
There is only one consensus protocol in the world, which is Paxos, and all other consensus algorithms are degenerate versions of Paxos—— Mike Burrows, author of Google Chubby
Paxos is a message passing based consensus negotiation algorithm proposed by Leslie Lamport (also known as "La" in LaTeX), and is the most important theoretical foundation of distributed systems today, almost synonymous with the word "consensus". This extremely high evaluation comes from the paper proposing the Raft algorithm, which is more significant. Although the author believes that Mike Burrows' statement is somewhat exaggerated, without Paxos, subsequent algorithms such as Raft and ZAB, distributed coordination frameworks such as ZooKeeper and ETCD, and various distributed applications based on this foundation such as Hadoop and Consul are likely to be delayed for several years.
# The Birth of Paxos
In order to explain the Paxos algorithm clearly, Lamport invented a Polis named "Paxos". The city-state made laws in accordance with the democratic system, but there was no centralized full-time legislature. Instead, it relied on the "Part Time Parliament" to complete the legislation. It could not guarantee that all citizens in the city-state would be able to understand new legal proposals in a timely manner, nor could it guarantee that residents would vote for proposals in a timely manner. The goal of the Paxos algorithm is to enable the city-state to reach a consensus based on the principle of the minority obeying the majority, even though every resident does not promise to participate in a timely manner. However, Paxos algorithm does not consider the Byzantine fault, that is, it is assumed that information may be lost or delayed, but will not be wrongly transmitted.
Lamport first published the Paxos algorithm in 1990 and chose the paper title "The Part Time Paragraph". Because the algorithm itself is extremely complex, using the Polis as a metaphor makes the description more obscure. The three reviewers of the paper unanimously asked him to delete the story of the Polis. This made Lamport feel quite unhappy and decided to withdraw the manuscript, so when Paxos was first proposed, there was no response. Eight years later (1998), Lamport reorganized this article and submitted it to ACM Transactions on Computer Systems. The successful publication of this paper has indeed attracted some people to study Lamport's reputation, but not many people can understand what he is talking about. Three years later (2001), Lamport believed that the first two papers did not cause response because his peers could not understand his sense of humor in telling stories with "Polis", so this time he published an article on SIGACT News under the title "Paxos Made Simple", gave up the metaphor of "Polis", and tried to use (he thought) simple and direct Introduce the Paxos algorithm in a highly readable way. Although the situation is slightly better than the previous two, in terms of the level of attention Paxos should have received, this time it can only be considered a few applicants. This experience that sounds like an online joke was posted on Lamport's personal website in the form of self deprecation. Although we, as descendants, should respect the Laozi of Lamport, when I opened the paper on "Paxos Made Simple" and saw the "abstract" with only the sentence "The Paxos algorithm, when presented in plain English, is very simple.
Although Lamport himself failed to make most of his peers understand Paxos in three consecutive articles, in 2006, Paxos was used in distributed systems such as Google's Chubby, Megastore, and Spanner to solve the problem of distributed consensus. After organizing it into a formal paper for publication, it benefited from Google's industry influence and was fueled by Chubby's slightly exaggerated but eye-catching evaluation by author Mike Burrows, The Paxos algorithm overnight became the hottest concept in the distributed branch of computer science and began to be studied by many in the academic community. Lamport himself won the Turing Award in 2013 for his outstanding theoretical contributions to distributed systems, and then came the story of Paxos' brilliant performance in blockchain, distributed systems, cloud computing and other fields.
# Algorithm process
In this article, Paxos specifically refers to the earliest Basic Paxos algorithm
The Paxos algorithm divides nodes in distributed systems into three categories.
- Proposal node: Refers to as a Proposer, a node that proposes to set a value. The behavior of setting a value is called Proposal, and once the value is successfully set, it will not be lost or changed. Note that Paxos is a typical algorithm designed based on the operation transition model rather than the state transition model. Do not compare the "set value" here to the variable assignment operation in the program, but rather to the logging operation. In the Raft algorithm introduced later, "submitting" is directly referred to as "logging".
- Decision node: called Acceptor, it is the node that responds to a proposal and determines whether it can be voted on and accepted. Once a proposal is accepted by more than half of the decision nodes, it is considered approved. The approval of the proposal means that the value cannot be changed or lost, and ultimately all nodes will accept it.
- Record node: referred to as Learner, it does not participate in proposals or decisions, but simply learns from proposals and decision nodes that have already reached consensus. For example, when a minority node recovers from a network partition, it will enter this state.
In a distributed system using the Paxos algorithm, all nodes are equal and can assume one or more of the above roles. However, to ensure a clear majority, the number of decision nodes should be set to an odd number, and during system initialization, each node in the network should know the number, address, and other information of all decision nodes in the entire network.
In a distributed environment, if we say that each node "reaches an agreement on a certain value (proposal)," we mean that "there is no scenario where one value is A at a certain moment and another value is B. The complexity of solving this problem mainly comes from the joint influence of the following two factors.
- The communication between various nodes within the system is unreliable, whether it is for proposal nodes attempting to set data or decision nodes deciding whether to approve the setting operation. The information sent and received may be delayed in delivery or may be lost, without considering the possibility of message transmission errors.
- The access of various users outside the system is concurrent. If the system only has one user or only performs serial access to the system at a time, simply applying the Quorum mechanism and a few nodes obeying the majority nodes is sufficient to ensure that the values are correctly read and written.
The first point is the objective phenomenon in network communication, which is also a problem that all consensus algorithms need to focus on solving. For the second point, a detailed explanation is as follows. Now we are talking about the problem of "shared data for concurrent operations in a distributed environment". Even if we do not consider whether it is in a distributed environment first, we only consider concurrent operations. Suppose there is a variable i whose value is currently stored in the system is 2, and at the same time, there are external requests A and B to send operation instructions to the system separately, "add 1 to the value of i" and "multiply the value of i by 3". If no Concurrency control is added, it is possible to get "(2+1) × 3=9 "and" 2 × The two possible outcomes are 3+1=7. Therefore, concurrent modifications to the same variable must be locked before operation, and requests from A and B cannot be processed alternately. This can also be said to be a basic common sense in program design. In a distributed environment, due to the communication failure that may occur at any time in the distributed system, if a node crashes and loses contact after obtaining the lock and before releasing the lock, the entire operation will be blocked by an infinite wait. Because locking in this algorithm is not exactly equivalent to locking in Concurrency control by mutex, it must also provide a mechanism that other nodes can preempt the lock, To avoid deadlock caused by communication issues.
To address this issue, locks in distributed environments must be preemptable. The Paxos algorithm consists of two stages, and the first stage of 'Prepare' is equivalent to the process of preempting locks. If a proposal node is ready to initiate a proposal, it must first broadcast a license application (called a Prepare request) to all decision nodes. The Prepare request of the proposal node will be accompanied by a globally unique and monotonically increasing number n as the proposal ID. After receiving it, the decision node will give the proposal node two promises and one response.
- Two commitments refer to:
- Promise not to accept Prepare requests with a proposal ID less than or equal to n;
- Promise not to accept Accept requests with a proposal ID less than n.
- A response refers to:
- On the premise of not violating previous commitments, reply to the value and proposal ID set by the proposal with the highest ID among the approved proposals. If the value has never been set by any proposal, return a null value. If the commitment made earlier is violated, that is, the proposal ID received is not the maximum ID received by the decision node, then it is allowed to ignore this Prepare request directly.
After the proposal node receives a response from the majority decision node (referred to as the Promise response), the second stage of the "Accept" process can begin. At this point, there are two possible outcomes:
- If the proposal node finds that all responding decision nodes have not previously approved the value (i.e. empty), it indicates that it is the first node to set the value and can freely decide the value to be set. The selected value and proposal ID are combined into a binary "(id, value)" and broadcasted to all decision nodes again (referred to as an Accept request);
- If the proposal node discovers that at least one of the responding decision nodes already contains a value in their response, it cannot take any value arbitrarily. Instead, it must unconditionally find the value with the highest proposal ID from the response and receive it, forming a binary "(id, maxAcceptValue)" that is broadcasted to all decision nodes again (called an Accept request).
When each decision node receives an Accept request, it will receive and persist the current proposal ID and the values attached to the proposal without violating previous commitments. If the commitment made earlier is violated, that is, the proposal ID received is not the largest ID received by the decision node, then it is allowed to ignore this Accept request directly.
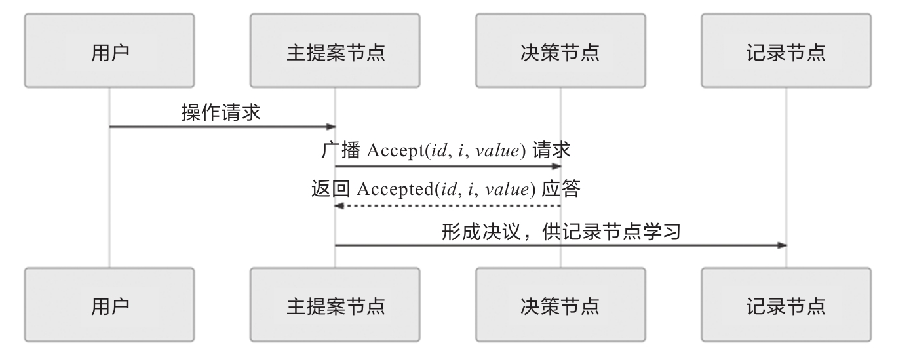
When the proposal node receives a response from the majority decision node (referred to as Accepted response), the negotiation ends, consensus resolution is formed, and the formed resolution is then sent to all record nodes for learning. The sequence diagram of the entire process is shown in the figure.
This concludes the workflow of the entire Paxos algorithm.

# Multi Paxos
The livelock problem in Basic Paxos is that two proposal nodes compete to propose their own proposals, seizing the modification permission of the same value, causing the entire system to continuously "repeatedly jump" and appear to be locked externally. In addition, the author also mentioned a viewpoint that the complexity of distributed consensus mainly comes from two major factors: the unreliability of the network and the concurrency of requests. The livelock problem and the troubles encountered in many Basic Paxos exception scenarios can be seen as the complex problem caused by the ability of any proposal node to propose proposals completely equally and concurrently with other nodes. To this end, Lamport proposed an improved version of Paxos - the Multi Paxos algorithm, hoping to find a way to achieve the best of both worlds, which not only does not violate the principle of "equality among nodes" in Paxos, but also achieves a distinction between primary and secondary in the proposal nodes, limiting each node to have uncontrollable proposal rights. These two goals sound contradictory, but the election in the real world is very consistent with the situation of selecting Opinion leader in equal nodes.
The core improvement of Multi Paxos on Basic Paxos is the addition of a "host selection" process. The proposal node will determine whether there is a host proposal node in all nodes in the current network through timed polling (heartbeat). Once no host node is found, the node will use the two rounds of network interaction defined in Basic Paxos to prepare and approve after the heartbeat expires, broadcasting its request to run for the host node to all other nodes, I hope that the entire distributed system can reach a consensus through negotiation on the matter of "I as the main node". If approved by the majority of the decision-making nodes, the election will be declared successful. After the election is completed, unless the main node loses contact and initiates a re election, only the main node itself can propose proposals from now on. At this point, no matter which proposal node receives the client's operation request, it will forward the request to the main node to complete the proposal. When the main node proposes, there is no need to go through the preparation process again, because it can be considered that after the preparation during the election, subsequent proposals are all a series of approval processes for the same proposal ID. It can also be easily understood as after selecting the master, there will be no other nodes competing with it, which is equivalent to an orderly operation in a non concurrent environment. Therefore, in order to reach a consensus on a certain value in the system, only one approved interaction is required, as shown in the figure.
 Some people may have noticed that at this point, the binary (id, value) has become a triple (id, i, value), because it is necessary to add a "term number" to the main node, which must be strictly monotonically increasing to cope with the main node's recovery after being trapped in a network partition. However, some other nodes still have a majority and have already completed the re selection of the main node. In this case, the main node with the larger term number must prevail. After the node is supported by the selection mechanism, overall, it can further simplify the role of the node, without distinguishing between proposal, decision, and record nodes. Instead, all nodes are replaced by "nodes", with only the difference between the leader and follower. At this time, the negotiation consensus sequence diagram is shown in the figure.
Some people may have noticed that at this point, the binary (id, value) has become a triple (id, i, value), because it is necessary to add a "term number" to the main node, which must be strictly monotonically increasing to cope with the main node's recovery after being trapped in a network partition. However, some other nodes still have a majority and have already completed the re selection of the main node. In this case, the main node with the larger term number must prevail. After the node is supported by the selection mechanism, overall, it can further simplify the role of the node, without distinguishing between proposal, decision, and record nodes. Instead, all nodes are replaced by "nodes", with only the difference between the leader and follower. At this time, the negotiation consensus sequence diagram is shown in the figure.
Let's reconsider the problem of "how to achieve consensus on a certain value in a distributed system" from a different perspective. We can divide the problem into three sub problems to consider, which can prove (the specific proof is not listed here, and interested readers can refer to Raft's article) that when the following three problems are solved simultaneously, it is equivalent to reaching consensus:
- How to select the leader election;
- How to replicate data to various nodes (Entity Replication);
- How to ensure the safety of the process.
Although the selection problem still involves many engineering details, such as heartbeat, random timeout, parallel election, etc., if you only talk about the principles, if you have understood the operating steps of the Paxos algorithm, you will not have any doubts about the selection problem, because this is essentially just a consensus reached by a distributed system on who will be the main node, We have already discussed in the previous section how distributed systems can reach a consensus on one thing, so we will not go into detail here. Now, we will directly address the replication problem of data (proposals in Paxos, logs in Raft) between various nodes in the network.
 Under normal circumstances, the client initiates an operation request to the master node, such as "setting a certain value to X". At this time, the master node writes X to its own change log, but does not submit it first. Then, in the next heartbeat packet, the information about changing X is broadcasted to all slave nodes, and the slave node is required to reply with a "confirm receipt" message. After the slave node receives the information, the operation is written to its own change log, Then, a "confirm receipt" message is sent to the master node. After receiving more than half of the receipt messages, the master node submits its own changes, responds to the client, and broadcasts messages that can be submitted to the slave node. After receiving the submission message, the slave node submits its own changes. At this point, the replication of data between nodes is declared complete.
Under normal circumstances, the client initiates an operation request to the master node, such as "setting a certain value to X". At this time, the master node writes X to its own change log, but does not submit it first. Then, in the next heartbeat packet, the information about changing X is broadcasted to all slave nodes, and the slave node is required to reply with a "confirm receipt" message. After the slave node receives the information, the operation is written to its own change log, Then, a "confirm receipt" message is sent to the master node. After receiving more than half of the receipt messages, the master node submits its own changes, responds to the client, and broadcasts messages that can be submitted to the slave node. After receiving the submission message, the slave node submits its own changes. At this point, the replication of data between nodes is declared complete.
In abnormal situations, the network experiences partitioning and some nodes are disconnected. However, as long as the number of nodes that can still function properly meets the requirements of the majority (more than half), the distributed system can function normally. At this time, the data replication process is as follows.
- Assuming there are five nodes, S1, S2, S3, S4, and S5, S1 is the primary node. Due to network failures, S1, S2, and S3, S4, and S5 cannot communicate with each other, forming a network partition.
- After a period of time, one of the three nodes, S3, S4, and S5 (such as S3), first reaches the heartbeat timeout threshold and learns that there is no longer a master node in the current partition. It sends a broadcast to all nodes and receives approval responses from S4 and S5 nodes. With a total of three votes, it obtains approval from the majority and the election is successful. At this time, both S1 and S3 master nodes will exist in the system, But due to network partitioning, they will not be aware of each other's existence.
- In this case, the client initiates an operation request.
- If the client connects to either S1 or S2, it will be handled by S1, but since the operation can only receive responses from up to two nodes and does not constitute approval from the majority, any changes cannot be successfully submitted.
- If the client connects to one of S3, S4, or S5, it will be processed by S3. At this point, the operation can obtain responses from up to three nodes, forming the approval of the majority, which is valid. Changes can be submitted, indicating that the system can continue to provide services.
- In fact, the above two scenarios rarely coexist. Network partition is caused by software, hardware or network failure. Internal network partition occurs, but it is rare that two partitions can still communicate with clients of external network normally. More scenarios are where the algorithm can tolerate some nodes being offline in the network. According to this example, if two nodes are offline, the system can still function normally. If three nodes are offline, the remaining two nodes cannot continue to provide services.
- Assuming that the fault is now restored, the partition is lifted, and the five nodes can communicate again:
- S1 and S3 both send heartbeat packets to all nodes. From their respective heartbeats, it can be inferred that S3 has a larger term number among the two master nodes, which is the latest. At this time, all five nodes only acknowledge S3 as the only master node.
- S1 and S2 roll back all their uncommitted changes.
- S1 and S2 obtain all changes that occurred during their disconnection from the heartbeat packets sent by the master node, submit the changes, and write them to the local disk.
- At this point, the state of each node in the distributed system reaches a final consensus.
Let's take a look at the third question: "How to ensure that the process is safe". Do you feel the difference between this question and the first two questions? Choosing the host and replicating data are very specific behaviors, but "security" is very vague. What is considered secure or not?
In distributed theory, safety and liveness are predefined terms that are generally translated into "agreement" and "termination" in professional literature. These two concepts were first proposed by Lamport, and their definitions are as follows.
- Safety: All bad things will not happen.
- Liveness: All good things will eventually happen, but I don't know when.
We will not dwell on rigorous definitions here, but will still illustrate their specific meanings through examples. For example, taking the selection problem as an example, protocol ensures that the result of the selection must have and only have a unique main node, and it is impossible to have two main nodes at the same time; And termination must ensure that the selection process can end at a certain time. From the previous introduction to livelocks, it can be seen that there are theoretical flaws in the selection of the main node in the attribute of termination, which may result in the inability to select a clear main node due to livelocks. Therefore, the Raft paper only wrote about the guarantee of safety, but due to the processing in engineering implementation, it is almost impossible to encounter termination issues in reality.
The above approach, which decomposes consensus problems into three issues: "host selection," "replication," and "security," is called the "Raft algorithm" (proposed in Raft's "A Consensus Algorithm That Can Be Understood"). It was awarded the Best Paper at the USENIX ATC 2014 conference and later became the implementation foundation for important distributed programs such as ETCD, LogCabinet, and Consul. ZooKeeper's ZAB algorithm is also very similar to Raft's approach, These algorithms are considered equivalent derivative implementations of Multi Paxos.
# Gossip Protocol
Paxos, Raft, ZAB, and other distributed algorithms are often referred to as "strong consistency" distributed consensus protocols. In fact, this description may be flawed, but we all understand that its meaning is: "Although internal nodes in the system can have inconsistent states, from the external perspective, inconsistent situations will not be observed, so the system as a whole is strong consistency, There is another kind of distributed consensus protocol called "Eventual consistency", which indicates that the inconsistent state in the system may be directly observed by the outside in a certain time. A typical and extremely common ultimately consistent distributed system is the DNS system, which may not be consistent with the actual domain name translation results until the TTL cached by each node expires. In this section, the author will introduce another representative "Eventual consistency" distributed consensus protocol, Gossip protocol, which is applied in Bitcoin network and many important distributed frameworks.
Gossip was first proposed by Palo Alto Research Center of Xerox in the paper "Epidemic Algorithms for Replicated Database Maintenance", which is an algorithm for Distributed database to replicate synchronous data between multiple nodes. From the title of the paper, it can be seen that initially it was called "Epidemic Algorithm", but it was not very elegant. Today, the name "Gossip" is more commonly used. In addition, it has other names such as "Rumor Algorithm", "Bagua Algorithm", and "Plague Algorithm", which vividly reflect the characteristics of Gossip: the information to be synchronized spreads like rumors, and viruses spread like viruses.
The author also refers to Gossip as a "consensus protocol" according to convention, but first of all, it must be emphasized that it is not directly equivalent to consensus algorithms such as Paxos and Raft. It is only based on Gossip that certain methods can be used to achieve goals similar to Paxos and Raft. A typical example is the use of the Gossip protocol in Bitcoin networks, which is used to synchronize block headers and block bodies among distributed nodes. This is the foundation for the entire network to exchange information normally, but it cannot be called consensus; Then Bitcoin uses Proof of work (PoW) to reach a consensus on "who will account for this block" throughout the network, so that this goal can be considered consistent with the goals of Paxos and Raft.
Next, let's learn about the specific work process of Gossip. Compared to algorithms such as Paxos and Raft, the process of Gossip is very simple and can be seen as a simple loop of the following two steps.
- If there is a certain piece of information that needs to be propagated across all nodes in the entire network, starting from the information source, select a fixed propagation period (such as 1 second), and randomly select k nodes connected to it (called Fan Out) to propagate the message.
- After each node receives a message, if it has not received it before, in the next cycle, the node will send the same message to k adjacent nodes except for the node that sent the message to it, until all nodes in the network finally receive the message. Although this process may take some time, in theory, all nodes in the network will ultimately have the same message.
According to the process description of Gossip, we can easily find that Gossip has almost no requirements for the connectivity and stability of network nodes. It initially only partially connected some nodes of the network to a partial connected network, rather than relying on a fully connected network as a prerequisite; Able to tolerate arbitrary increase or decrease of nodes on the network, as well as arbitrary downtime or restart; The status of newly added or restarted nodes will eventually be synchronized with other nodes to reach a consensus. Gossip regards all nodes on the network as equal and ordinary members, without any concept of centralized nodes or master nodes. These characteristics make Gossip highly robust and very suitable for application in the public internet.
At the same time, we can easily identify the shortcomings of Gossip. The message ultimately reaches the entire network through multiple rounds of dissemination, so there is inevitably a situation where the states of each node in the network are inconsistent. Moreover, since the nodes that send the message are randomly selected, although the statistically significant propagation rate can be measured as a whole, for individual messages, it is not possible to accurately predict how long it will take to achieve network consensus. Another drawback is the redundancy of messages, which is also due to the random selection of nodes to send messages. Therefore, there is inevitably a situation where messages are repeatedly sent to the same node, increasing the transmission pressure of the network and bringing additional processing load to the message nodes.